20201113_TIL
by Haebin Seo
오늘 한 일
- java 공부
- 자료구조
- Array (배열)
- fixed length
- 물리적인 위치와 논리적인 위치가 동일하다.
- [장점] 인덱스 연산. 연산을 통해 원하는 위치에 접근하기 용이하다.
- [단점] 연속성을 유지해야하므로 중간을 비울 수 없다. 삽입, 삭제 $O(n)$
- JDK의 ArrayList, Vector로 구현가능
길이 연장이 불가능하므로, 선언한 길이 이상의 데이터를 저장하려면 재할당해서 사용해야 한다. 예전에는 Vector를 사용했으나 요즘에는 더 최적화된 ArrayList를 사용한다. Vector는 동기화를 지원한다.
- Linked List
- 물리적인 위치 != 논리적인 위치
- 삽입, 삭제에 필요한 연산량이 배열보다 적다.
- 인덱스 연산이 불가능한다. 탐색 $O(n)$
- JDK의 LinkedList로 구현가능
- Stack
- LIFO (Last In First Out)
- top
- push(), pop()
- peek(): 스택 맨 위의 원소를 반환(reference). 삭제는 x.
- JDK의 Stack으로 구현가능
- Queue
- FIFO (First In First Out)
- front, rear
- enqueue(), dequeue()
- JDK의 ArrayList, Vector, LinkedList로 구현가능
- Binary Search Tree
- BST의 모든 노드는 각 노드의 left subtree의 노드보다 크고 right subtree의 노드보다 작다.
- 중복을 허용하지 않는다.
- auto-balancing: AVL Tree, Red-Black Tree (java에서는 Red-Black tree 사용)
- 순회:
in-order(Left Child -> Node -> Right Child)
pre-order(Node -> Left Child -> Right Child)
post-order(Left Child -> Right Child -> Node) - 순회를 통해 정렬된 결과를 얻을 수 있다. (in-order: 오름차순, 좌우 반전 트리는 내림차순)
- JDK의 Treeset, TreeMap(Red-Black Tree)로 구현가능
- Hashing
- 산술 연산을 이용한 검색 방식
- 평균 시간 복잡도 $O(1)$
- JDK의 HashMap, HashSet으로 구현가능
- HashTable은 동기화를 지원하지만 이로 인한 overhead가 발생한다.
- Array (배열)
-
컬렉션 프레임워크
프로그램 구현에 필요한 자료구조를 구현해 놓은 라이브러리로 java.util 패키지에 구현되어 있다. 개발에 소요되는 시간을 절역하면서 최적화된 알고리즘을 사용할 수 있다. 여러 인터페이스와 구현 클래스 사용 방법을 이해해야 한다.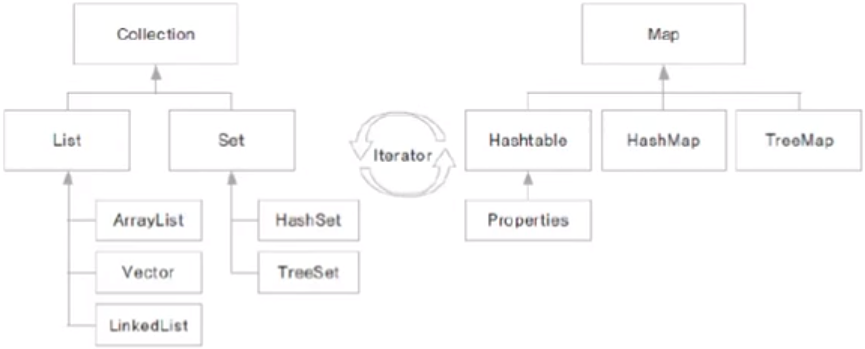
- TreeMap은 key를 node의 값으로 사용해 tree를 이룬다.
- Properties는 IO에서 key-value pari를 다루는데 사용된다.
- 모든 객체들은 iterator 인터페이스를 활용해 순회할 수 있다.
- Collection 인터페이스
하나의 객체를 관리하기 위한 메서드가 선언된 인터페이스이다. 하위에 List와 Set 인터페이스가 존재하고 여러 클래스들이 Collection 인터페이스를 구현한다.분류 설명 List 인터페이스 순서가 있는 자료 관리. 중복 허용. 이 인터페이스를 구현한 클래스는 ArrayList, Vector, LinkedList, Stack, Queue 등이 있음 Set 인터페이스 순서가 정해져 있지 않음. 중복을 허용하지 않음. 이 인터페이스를 구현한 클래스는 HashSet, TreeSet 등이 있음 - Collection 인터페이스에 선언된 주요 메서드
메서드 설명 boolean add(E e) Collection에 객체를 추가합니다. void clear() Collection의 모든 객체를 제거합니다. iterator<E> iterator Collection을 순환할 반복자(iterator)를 반환합니다. boolean remove(Object o) Collection에 매개변수에 해당하는 인스턴스가 존재하면 제거합니다. int size() Collection에 있는 요소의 개수를 반환합니다.
- Collection 인터페이스에 선언된 주요 메서드
-
List 인터페이스
Collection 하위 인터페이스로, 객체를 순서에 따라 저장하고 관리하는데 필요한 메서드가 선언되어 있다. 즉 배열의 기능을 구현하기 위한 인터페이스라 볼 수 있다. ArrayList, Vector, LinkedList 등이 많이 쓰인다.- ArrayList와 Vector
객체 배열을 구현한 클래스이다. 일반적으로 ArrayList를 더 많이 사용하지만 멀티 쓰레드 상태에서 리소스에 대한 동기화가 필요한 경우에는 Vector를 사용한다. ArrayList에 동기화 기능이 추가되어야 하는 경우에는 Collections.synchronizedList를 사용한다.List<String> list = Collections.synchronizedList(new ArrayList<String>());cf) 동기화: 두 개의 쓰레드가 동시에 하나의 리소스에 접근할 때(critical section), 데이터에 오류가 발생하지 않도록 순서를 보장함 (프로세스 내의 쓰레드들은 메모리(code, data)를 공유하므로). vector의 메서드에는 synchronized 예약어가 붙는다. cf2) Collections.synchronizedList에 관한 읽을거리 https://okky.kr/article/279692
-
LinkedList
-
Stack과 Queue
Stack과 Queue의 기능은 구현된 클래스가 있지만 ArrayList나 LinkedList를 활용해서 사용할 수도 있다. - iterator 사용하여 순회하기
iterator는 Collection의 개체를 순회하는 인터페이스이다. iterator는 collections의 iterator() 메서드 호출을 통해 얻을 수 있다.Iterator<Member> iter = memberArrayLIst.iterator(); // 제네릭 타입 사용 가능선언된 메서드는 다음과 같다.
메서드 설명 boolean hashNext() 이후에 요소가 더 있는지를 체크하는 메서드이며, 요소가 있다면 true를 반환한다. E next() 다음에 있는 요소를 반환한다. -1 에서 시작하는 인덱스 포인터 정도로 생각하면 편하다.
- ArrayList와 Vector
- 자료구조
참조
- Do it! 자바 프로그래밍 입문: https://www.inflearn.com/course/자바-프로그래밍-입문/dashboard
Subscribe via RSS